
大数据
定义
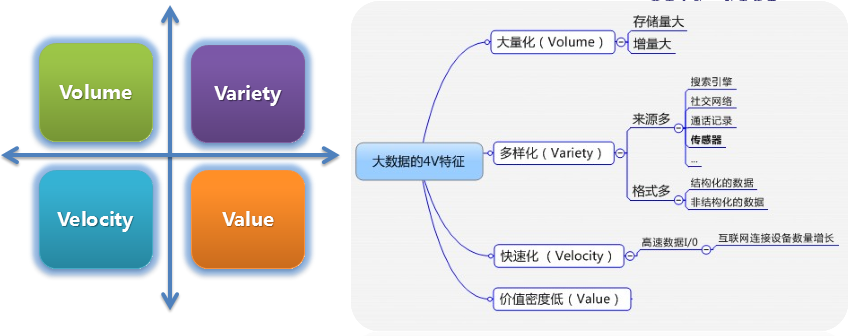
一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。
特征
容量(Volume)
数据的大小决定所考虑的数据的价值和潜在的信息;
种类(Variety)
数据类型的多样性;
速度(Velocity)
指获得数据的速度;
可变性(Variability)
妨碍了处理和有效地管理数据的过程;
真实性(Veracity)
数据的质量;
复杂性(Complexity)
数据量巨大,来源多渠道;
价值(value)
合理运用大数据,以低成本创造高价值。
结构
在以云计算为代表的技术创新大幕的衬托下,这些原本看起来很难收集和使用的数据开始容易被利用起来了,通过各行各业的不断创新,大数据会逐步为人类创造更多的价值。
理论
技术
云计算、分布式处理技术、存储技术、感知技术。
实践
大数据的最终价值体现。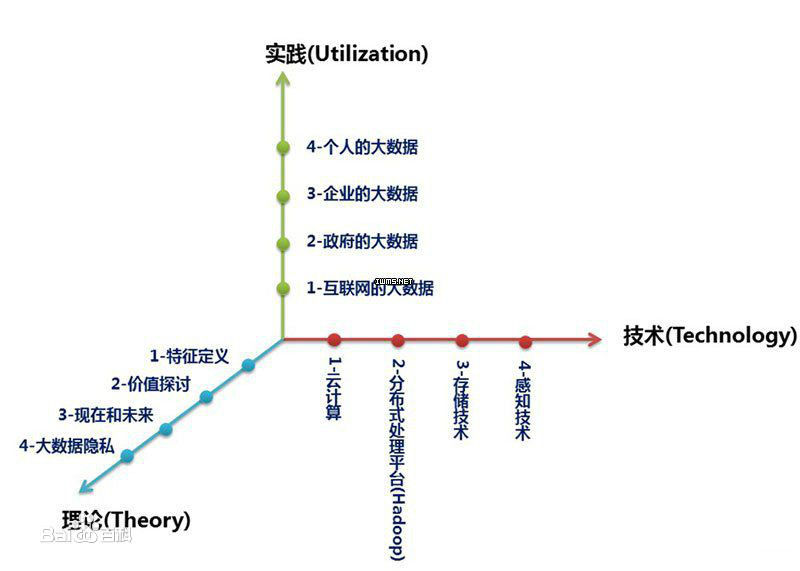
趋势
趋势一:数据的资源化
趋势二:与云计算的深度结合
趋势三:科学理论的突破
数据挖掘、机器学习、人工智能
趋势四:数据科学和数据联盟的成立
趋势五:数据泄露泛滥
趋势六:数据管理成为核心竞争力
趋势七:数据质量是BI(商业智能)成功的关键
趋势八:数据生态系统复合化程度加强
大数据4V特征
大数据案例
Google分布式计算的三驾马车
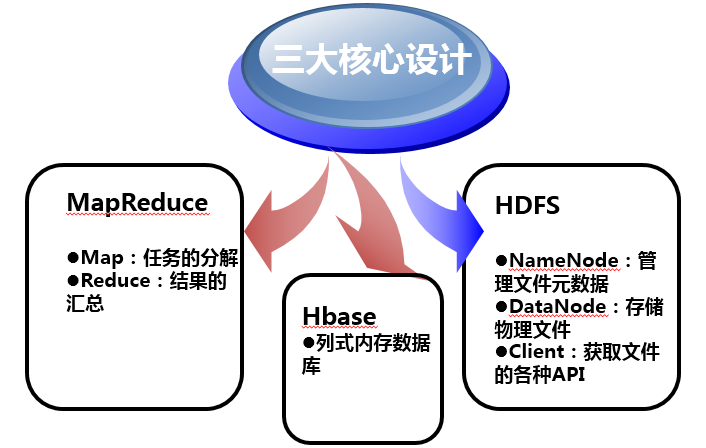
- Google File System用来解决数据存储的问题,采用N多台廉价的电脑,使用冗余(也就是一份文件保存多份在不同的电脑之上)的方式,来取得读写速度与数据安全并存的结果。
- Map-Reduce说穿了就是函数式编程,把所有的操作都分成两类,map与reduce,map用来将数据分成多份,分开处理,reduce将处理后的结果进行归并,得到最终的结果。
- BigTable是在分布式系统上存储结构化数据的一个解决方案,解决了巨大的Table的管理、负载均衡的问题。
Hadoop
体系架构
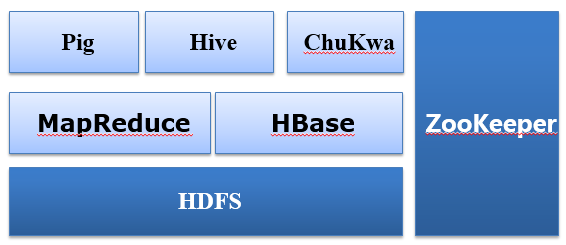
核心设计
关键词
云计算、数据挖掘、机器学习、分布式处理、存储、感知
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.